RユーザーのためのMySQL環境構築~データベース構築からRとの接続まで~
はじめに
ここではMySQLの環境構築の内容をまとめておく。私のような大学院の研究でデータ分析を始め、就職してからはSQLも触らないといけなくなったものの、データベースとかさっぱりで、SQLの練習をしようにもデータベースの環境構築にてこづっている分析担当者のお役に立てれば幸いである。MySQLの環境構築からRでの接続までをできるようにする。環境はMac、MySQL8.0を想定している。
Homebrewの準備
まずはHomebrewをインストールする。Homebrewは、Mac用のパッケージマネージャーで、MySQLのインストールに必要なので、まずこれをインストールしていく。Homebrewは、オープンソースのソフトウェアをターミナルからインストールしたり、アンインストールしたりできる。Homebrewの文法は基本的には、下記のような感じ。
brew <command> [<options>] [<formula>]
なので、後にMySQLをインストールするときはこんな感じである。Homebrewコマンドで、MySQLをインストールしてください、ということである。
brew install mysql
では、ターミナルを起動し、brew --versionを実行する。バージョンが表示されればインストール自体はされている。
$ brew --version # Homebrew 2.1.11 # Homebrew/homebrew-core (git revision 8eeed; last commit 2019-09-21) # Homebrew/homebrew-cask (git revision 7fd56d; last commit 2019-09-22)
インストールされている場合であっても、下記コマンドで最新の状態にHomebrewをアップデートしておく。
$ brew update
brew: command not foundと表示されていた場合は、Homebrewがまだインストールされていないので、下記のHomebrewをインストールするコマンドを実行する。コマンドはHomebrewのサイトからも入手できる。インストール後にbrew --versionを実行して、バージョンが表示されれば問題ない。
$ /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
MySQL8.0のインストール
MySQL8.0のインストールを行う。brew info mysqlでインストールした際にどのバージョンがインストールされるのかを確認する。現状はmysql: stable 8.0.17である。
$ brew info mysql # mysql: stable 8.0.17 (bottled)
ではMySQL8.0をインストールする。brew install mysqlを実行する。
$ brew install mysql
mysql --versionを実行し、インストールしたMySQLのバージョンを確認しておく。MySQL8.0がインストールできている。MySQLのインストールはこれで終わりである。後で少し設定をいじるが、先にMySQLの統合環境である、MySQL WorkBenchをインストールする。
$ mysql --version # mysql Ver 8.0.17 for osx10.14 on x86_64 (Homebrew)
MySQL WorkBenchのインストール
MySQL WorkBenchのインストールはこのURLから行う。MacOSを選択し、"Download"をクリックする。

これではまだダウンロードできないので、画面左下の"No Thanks, just start my download"をクリックするとdmgファイルをダウンロードできる。
dmgファイルを実行し、MySQL WorkBenchをアプリケーションフォルダに移動する。MySQL WorkBenchを起動すると、このような画面になる。
MySQLのmy.cnfを修正
my.cnfを使って、MySQLに対する設定を行う。基礎MySQL ~その2~ my.cnf (設定ファイル)に詳しい内容が記載されている。この設定をしておかないと、日本語が文字化けしたりする。
まずはこのmy.cnfを修正するために、vimを起動して修正する。vimはLinuxのテキストエディターで、私のような人間からすると、非常に癖が強く、使い方が直感的ではないテキストエディターである。vimを使うときは「モード」を意識する必要がある。
下記のコマンドを実行し、iを押してインサートモードに切り替える。ターミナルの下部に現在のモードにが表示されているので、INSERTと表示されていれば、テキストを編集できる。
$ vim /usr/local/etc/my.cnf
# これの2行を下記の通り追記する。追記し終わったら、escでインサートモードを終了し、:wqを実行することで、コマンドモードに変更し、修正内容を保存する。ちなみに:(コマンドモード)w(write)q(quit)の略である。
# Default Homebrew MySQL server config [mysqld] # Only allow connections from localhost bind-address = 127.0.0.1 character-set-server=utf8 # これ default_authentication_plugin=mysql_native_password # これ
MySQLの初期設定
MySQLの初期設定を行う。mysql_secure_installationコマンドはセキュリティ設定のためのコマンドで、下記のことが設定できる。MySQL 5.7 をインストールしたら最初に行うセットアップに詳細が記載されている。バージョンの違いは気にしなくても問題ない。
- rootユーザーのパスワードの変更
- VALIDATE PASSWORDプラグインのインストール
- ポリシーに沿ったrootユーザーのパスワードの設定
- anonymousユーザーの削除
- リモートホストからrootユーザーでログインするのを禁止する設定
- testデータベースの削除
では、mysql.server startコマンドを実行し、MySQLを起動する。
$ mysql.server start # Starting MySQL # .. SUCCESS!
ちなみに、サーバーを止めたいときは、mysql.server stopで、再起動したいときはmysql.server restartを実行する。基本、作業しないときは停止させておく。
# サーバーの停止 $ mysql.server stop # サーバーの再起動 $ mysql.server restart # サーバーのステータスを確認 $ mysql.server status
それでは、mysql_secure_installationコマンドを実行する。
$ mysql_secure_installation
はじめはVALIDATE PASSWORD componentのプラグインをインストールしたいかどうかをきかれるので、yを実行。
Would you like to setup VALIDATE PASSWORD component? Press y|Y for Yes, any other key for No: y
その次は、パスワードポリシーの強固さのレベルを設定する。ここではStrongを使用するので2を実行。
There are three levels of password validation policy: 2 New password: ****************** Re-enter new password: ****************** # Estimated strength of the password: 100
設定したパスワードで続行するか聞いてくるので、yで続行。
Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No) : y
anonymousユーザーを削除するかどうか聞いてくるので、yで削除。
Remove anonymous users? (Press y|Y for Yes, any other key for No) : y
rootのログインをローカルからに制限するかを聞いてくるので、yで制限。
Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y
testデータベースを削除するかどうかを聞いてくるので、yで削除。
Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y
テーブルの権限を今、更新するかを聞いてくるので、yで更新。
Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y # All done!
All done!と表示されれば、mysql_secure_installationの設定は終了。mysql -u root -pというコマンドでMySQLにログインしてみる。これはパスワードを使用してrootユーザーでログインすることを意味する。
$ mysql -u root -p Enter password: *****************
ログインできたら、試しにshow databases;を実行してみる。データベースの一覧が表示される。
mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 4 rows in set (0.00 sec)
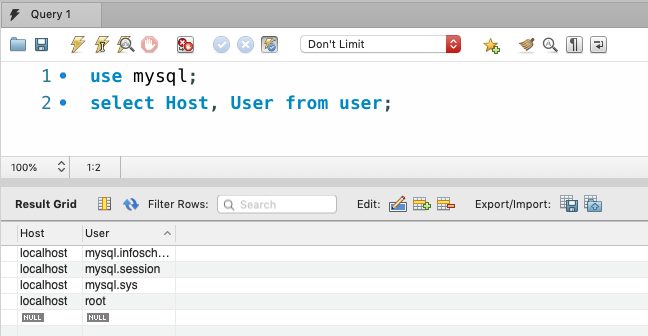
mysqlデータベースのuserテーブルを試しに覗いてみる。
use mysql; # Database changed mysql> select Host, User from user; +-----------+------------------+ | Host | User | +-----------+------------------+ | localhost | mysql.infoschema | | localhost | mysql.session | | localhost | mysql.sys | | localhost | root | +-----------+------------------+ 4 rows in set (0.00 sec)
ユーザーの種類
rootユーザーでログインしてみたものの、そもそもrootユーザーとは何か。MySQLにはユーザーの種類が「rootユーザ」「一般ユーザ」「匿名ユーザ」の3種類ある。
rootユーザーは、特別なアカウントで、ほぼすべてのファイルにアクセスできたり、作成、編集、削除が可能な権限を持つ。なので、データベースの管理者がrootユーザーを管理し、作業する人は管理者にgrantコマンドで一般ユーザーを作成してもらい、作業することになる。MySQL の権限のコマンドまとめ。を参照ください。
# すべてできる grant all on hoga_database.* to fuga_san@localhost identified by ‘*****’; # SELECT,INSERT,UPDATE,DELETEだけできる GRANT SELECT,INSERT,UPDATE,DELETE ON hoga_database.* TO fuga_san@'%' IDENTIFIED BY '*****'; # hoga_database : データベース名 # fuga_san : ユーザー名 # ***** : パスワード
今回の構築目的は練習なのでrootユーザーをそのまま使用する。
MySQL WorkBenchと接続
このままターミナルで作業できる人はいいのですが、私は作業しにくいので、MySQL WorkBenchに接続して作業する。MySQL WorkBenchを起動し、メニューの「Database >> connect to database」をクリック。
接続設定を行う。画像ではConnection Nameを入れ忘れているが、入力する。
- Connection Name : train
- Hostname : localhost
- Port : 3306
- Username : root
これで接続できるはず。

MySQLのパスワードを入力して「OK」。
さきほどターミナルで行ったクエリも実行できている。
データのインポート
データをインポートしていく。irisのデータをインポートしてみる。まずはテーブル定義を作成する。trainというデータベースを作成し、useコマンドで使用するデータベースを宣言する。
create database train; use train; CREATE TABLE iris( Sepal_Length DOUBLE NOT NULL, Sepal_Width DOUBLE NOT NULL, Petal_Length DOUBLE NOT NULL, Petal_Width DOUBLE NOT NULL, Species VARCHAR(255) NOT NULL, INDEX(Species) );
クエリを実行したあとは、「Refresh All」でスキーマを更新しておく。そうすれば、trainデータベースとirisテーブルが表示される。

irisを右クリックし、「Table Data Import Wizard」を選択。画面に従ってcsvのファイルパスを設定し、先程作成したirisテーブルにインポートしたいので、「Use existing table」を選択。
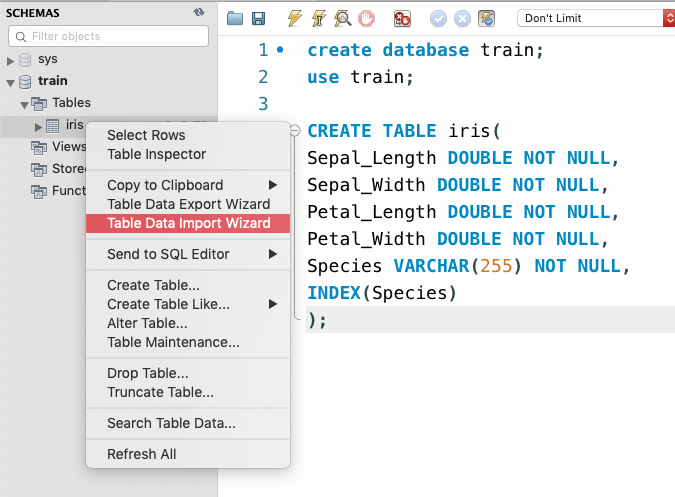
「Configure Import Settings」「Import Data」の設定も特に問題なければ「Next」。
データのインポートが完了したら、とりあえずselect * from iris;を実行してみると、データは問題なくインポートされている。

Rとの接続
最後にRとMySQLを接続して終わりにする。{DBI}と{RMySQL}を使用する。
library(DBI)
library(RMySQL)
# データベースとの接続設定
dbconnector <- dbConnect(drv = RMySQL::MySQL(),
dbname = "train", # データベース名
user = "root", # ユーザー名
password = "*****", # MySQLのパスワード
host = "127.0.0.1", # "localhost"でも問題ないはず
port = 3306) # ポート番号
data <- dbGetQuery(dbconnector, "select * from iris")
dim(data)
# [1] 150 5
head(data)
# Sepal_Length Sepal_Width Petal_Length Petal_Width Species
# 1 5.1 3.5 1.4 0.2 setosa
# 2 4.9 3.0 1.4 0.2 setosa
# 3 4.7 3.2 1.3 0.2 setosa
# 4 4.6 3.1 1.5 0.2 setosa
# 5 5.0 3.6 1.4 0.2 setosa
# 6 5.4 3.9 1.7 0.4 setosa
# 7 4.6 3.4 1.4 0.3 setosa
# 8 5.0 3.4 1.5 0.2 setosa
# 9 4.4 2.9 1.4 0.2 setosa
# 10 4.9 3.1 1.5 0.1 setosa
# ベータベースとの接続を切断
dbDisconnect(dbconnector)
# [1] TRUE
実際は{dbplyr}が{dplyr}のスクリプトをSQLに翻訳して(条件あり)、DBにクエリを飛ばしてくれるので、{dplyr}のスクリプトをそのまま書いてDBからデータを取得、集計できる。ウインドウ関数も対応している。こんな感じ。詳細は下記を参照。
library(dbplyr) library(dplyr) df1 #> <SQL> #> SELECT * #> FROM `df` df1 %>% group_by(x) %>% summarise(z = mean(y, na.rm = TRUE)) #> <SQL> #> SELECT `x`, AVG(`y`) AS `z` #> FROM `df` #> GROUP BY `x` spark_mtcars %>% mutate(cumsum = order_by(mpg, cumsum(mpg))) %>% show_query() #> <SQL> #> SELECT `mpg`, `cyl`, `disp`, `hp`, `drat`, `wt`, `qsec`, `vs`, `am`, `gear`, `carb`, #> sum(`mpg`) OVER (ORDER BY `mpg` ROWS UNBOUNDED PRECEDING) AS `cumsum` #> FROM `mtcars`
Pythonの単方向連結リスト
はじめに
データ構造の連結リストの勉強をしていて、頭の中がこんがらがったので、そのメモ。Rのことではないので、Pythonブログを作成した際に引っ越しするまでのメモ。
Unidirectional Linked List
from __future__ import annotations
from typing import Any
class Node(object):
def __init__(self, data: Any, next_node: Node = None):
self.data = data
self.next = next_node
class LinkedList(object):
def __init__(self, head=None) -> None:
self.head = head
def append(self, data: Any) -> None:
new_node = Node(data)
if self.head is None:
self.head = new_node
return
last_node = self.head
while last_node.next:
last_node = last_node.next
last_node.next = new_node
def insert(self, data: Any) -> None:
new_node = Node(data)
new_node.next = self.head
self.head = new_node
def print(self) -> None:
current_node = self.head
while current_node:
print(current_node.data)
current_node = current_node.next
def remove(self, data: Any) -> None:
current_node = self.head
if current_node and current_node.data == data:
self.head = current_node.next
current_node = None
return
previous_node = None
while current_node and current_node.data != data:
previous_node = current_node
current_node = current_node.next
if current_node is None:
return
previous_node.next = current_node.next
current_node = None
def reverse(self) -> None:
previous_node = None
current_node = self.head
while current_node:
next_node = current_node.next
current_node.next = previous_node
previous_node = current_node
current_node = next_node
self.head = previous_node
if __name__ == '__main__':
l = LinkedList()
l.append(10)
l.append(20)
l.append(30)
l.append(40)
l.insert(0)
l.append(50)
l.remove(20)
l.print()
# 50
# 40
# 30
# 10
# 0
下記の画像は、プログラムの正確な挙動ではない。各appendやInsert、removeのタイミングで、その前にどのような変数が保存されていて、どのような書き換えがあったのかのイメージ。





MySQLのイベントスケジューラーもどきをtask機能で作成する
Snowflakeとなにかをつないで、データ更新がうまく行くかどうか、検証環境を作りたい。"SNOWFLAKE_SAMPLE_DATA"."WEATHER"."HOURLY_16_TOTAL"というテーブルが自動更新されるようなので、これを使えば良いと思っていたけど、数年前からdeprecatedらしく、データが更新されていない。Snowflakeがまだよくわからないので、MySQLのイベントスケジューラーみたいな機能を使って、できないかと調べていたら、タスクという機能があるようで、それを使えば検証できそう。
下記、1分毎に1行インサートするタスクを作成し、起動するためのスクリプト。乱数系の関数とかをつかうと、サイレントエラー状態で、実行もうまく行かなかった。またドキュメントを時間あるときにでも読もう。
// タイムゾーン関連の設定 alter session set timestamp_type_mapping = 'TIMESTAMP_LTZ'; alter session set timezone = 'Asia/Tokyo'; // `task_demo.public.job_tracker`を作成 use role accountadmin; create or replace database task_demo; use schema public; CREATE SEQUENCE "TASK_DEMO"."PUBLIC".id_seq START 1 INCREMENT 1; //create or replace table job_tracker ( // id integer, // created_at timestamp, // val1 integer, // val2 integer //); //create or replace table join_tbl ( // id integer, // joined_val varchar(10) //); //insert into join_tbl(id, joined_val) values (1, 'tanaka'),(2, 'sato'),(3, 'suzuki'),(4, 'takahashi'),(5, 'Tom'); //insert into join_tbl(id, joined_val) values (47, 'cat'),(48, 'cat3'),(48, 'ca5t'); //select * from join_tbl; // select current_timestamp() // task1という名前のtaskを作成し、適当に値をインサートする create or replace task task1 warehouse = COMPUTE_WH schedule = '1 minute' as insert into job_tracker values ( id_seq.nextval, current_timestamp(), second(current_timestamp()) * hour(current_timestamp())::integer, hour(current_timestamp())::integer ); // task1を起動して確認 alter task task1 resume; show tasks; // 値がインサートされているかを確認 select * from job_tracker; // 役目を終えたらtask1を削除 drop task task1; drop table job_tracker; drop table join_tbl; drop database task_demo; select * from job_tracker; // select * from job_tracker left join join_tbl on job_tracker.id = join_tbl.id;
